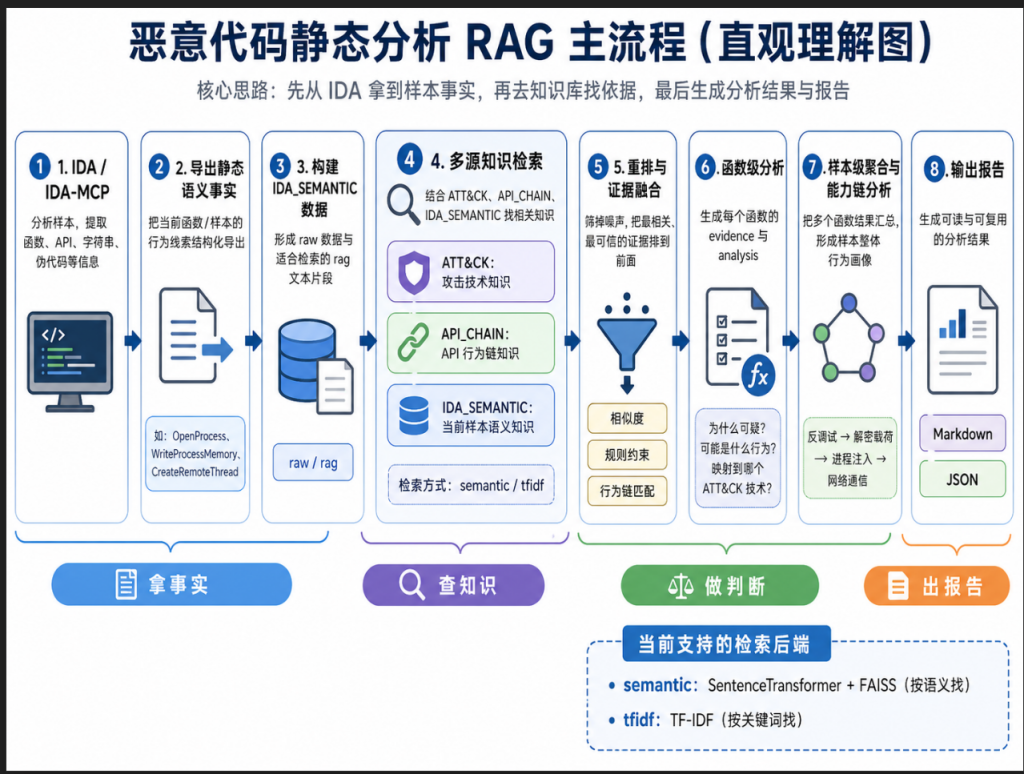
刚开始看整个工程流程的时候,其实会觉得有点绕:什么 IDA-MCP、IDA_SEMANTIC、ATT&CK、API_CHAIN、semantic + FAISS、TF-IDF,这些东西单独看都能理解一点,但串在一起的时候就容易乱。
所以这篇笔记主要想把当前工程的主流程梳理一下,用比较直观的方式说明:
系统到底是怎么从 IDA 里的函数信息,一步步生成函数分析结果和样本报告的。
一、整体思路
当前工程的核心逻辑其实可以简单理解为一句话:
先从 IDA 里拿到样本事实,再去知识库里找解释依据,最后生成分析结果和报告。
也就是说,系统并不是凭空判断一个函数是不是恶意行为,而是先拿到当前样本中的真实信息,比如函数、API 调用、字符串、伪代码摘要等内容,然后再结合已有的安全知识进行检索、匹配和分析。
当前工程中主要有三类知识源:
ATT&CK :告诉系统“这种行为在攻击框架里叫什么”
API_CHAIN :告诉系统“一组 API 调用通常代表什么恶意行为”
IDA_SEMANTIC :告诉系统“当前样本或函数自己实际做了什么”
可以简单画成这样:
当前样本事实 + 安全知识 + API 行为经验
↓
检索与匹配
↓
得到相关证据
↓
生成分析结论
二、IDA / IDA-MCP:系统入口
在人工逆向分析时,我们一般会先把样本拖进 IDA,然后查看函数列表、字符串、API 调用、交叉引用和反编译伪代码。
但是这些信息原本都停留在 IDA 里面,外部程序并不能直接使用。
比如在 IDA 里看到某个函数调用了:
OpenProcess
VirtualAllocEx
WriteProcessMemory
CreateRemoteThread
人工分析时,我们可能会判断:
这组 API 看起来像远程线程注入。
而在当前工程里,IDA-MCP 的作用就是把 IDA 里的这些静态分析信息导出来,让外部 Python 程序可以读取和处理。
所以可以理解为:
IDA :负责分析样本
IDA-MCP :负责把 IDA 里的分析结果导出来
Python 工程:负责后续检索、重排、生成报告
换句话说,IDA-MCP 就是 IDA 和外部分析系统之间的一座桥。
三、什么是“静态语义事实”
工程流程里有一步叫:
导出当前样本或当前函数的静态语义事实
这个名字看起来比较抽象,但其实很好理解。
所谓“静态语义事实”,就是:
不运行样本,仅根据 IDA 的反汇编、反编译结果提取出来的行为线索。
比如某个函数中出现了下面这些调用:
OpenProcess(...);
VirtualAllocEx(...);
WriteProcessMemory(...);
CreateRemoteThread(...);
那么系统可以把它整理成结构化数据:
{
"function": "sub_401000",
"apis": [
"OpenProcess",
"VirtualAllocEx",
"WriteProcessMemory",
"CreateRemoteThread"
],
"strings": [],
"possible_behavior": "process injection"
}
这里要注意一点:
这些内容还不是最终结论,而是原始证据。
它只是说明这个函数里确实出现了这些 API 调用,至于它是不是远程线程注入,还需要结合 API 行为链知识和 ATT&CK 知识进一步判断。
四、IDA_SEMANTIC raw / rag 数据
在工程里,IDA_SEMANTIC 数据又可以分成两类:
raw 数据
rag 数据
这两个名字看起来有点像,但用途不一样。
1. raw 数据
raw 数据更接近原始记录,保存得比较完整,方便后续回溯和调试。
例如:
{
"sample": "1.bin",
"function": "sub_401000",
"address": "0x401000",
"apis": [
"OpenProcess",
"VirtualAllocEx",
"WriteProcessMemory",
"CreateRemoteThread"
],
"strings": [],
"xrefs": [],
"summary": "该函数可能与远程线程注入相关"
}
这种数据偏工程化,主要用于保存当前样本的函数级分析事实。
2. rag 数据
rag 数据是为了后面的检索准备的。
RAG 检索通常不太适合直接吃一整块复杂 JSON,而更适合检索自然语言形式的文本片段。
所以系统会把 raw 数据整理成类似这样的文本:
函数 sub_401000 调用了 OpenProcess、VirtualAllocEx、WriteProcessMemory、CreateRemoteThread,
该 API 组合通常与远程线程注入、进程注入行为相关。
这样后续无论是使用 semantic + FAISS 语义检索,还是使用 TF-IDF 关键词检索,都更容易匹配到相关内容。
可以简单理解为:
raw 数据 = 原始档案,方便保存和回溯
rag 数据 = 知识卡片,方便检索和匹配
五、为什么要联合 ATT&CK / API_CHAIN / IDA_SEMANTIC 检索
单独看 IDA 导出的函数事实其实是不够的。
比如 IDA_SEMANTIC 中有这样一条事实:
当前函数调用了 OpenProcess、VirtualAllocEx、WriteProcessMemory、CreateRemoteThread。
这只能说明函数里有这些 API 调用。
但是系统还需要进一步知道:
这组 API 通常代表什么行为?
这个行为在 ATT&CK 中对应什么技术?
这种行为在分析报告里应该怎么描述?
所以就需要联合多个知识源进行检索。
1. ATT&CK 知识库
ATT&CK 主要提供攻击技术层面的解释。
比如:
T1055 Process Injection
Defense Evasion / Privilege Escalation
它的作用是告诉系统:
这个行为在攻击框架中属于哪类技术。
比如远程线程注入、进程注入、持久化、反调试、凭证访问等行为,都可以尝试映射到 ATT&CK 技术。
2. API_CHAIN 知识库
API_CHAIN 更贴近逆向分析经验。
比如:
OpenProcess -> VirtualAllocEx -> WriteProcessMemory -> CreateRemoteThread
这组调用链通常可以和远程线程注入相关联。
也就是说,API_CHAIN 负责告诉系统:
一组 API 连在一起,通常代表什么行为。
它不像 ATT&CK 那么偏框架,而是更接近我们平时分析样本时总结出来的经验规则。
3. IDA_SEMANTIC 知识库
IDA_SEMANTIC 记录的是当前样本自身的函数事实。
比如:
sub_401000 调用了 OpenProcess、VirtualAllocEx、WriteProcessMemory、CreateRemoteThread。
它的作用是告诉系统:
当前样本中确实出现了这些行为线索。
所以三类知识源可以这样理解:
ATT&CK :理论框架
API_CHAIN :逆向经验
IDA_SEMANTIC :当前样本事实
三者结合起来,系统才能从“函数调用了几个 API”,进一步推断出“该函数可能具备某种恶意能力”。
六、多源检索到底在检索什么
假设当前函数是:
sub_401000:
OpenProcess
VirtualAllocEx
WriteProcessMemory
CreateRemoteThread
系统可能会构造一个查询:
OpenProcess VirtualAllocEx WriteProcessMemory CreateRemoteThread process injection
然后分别去不同知识源里查找相关内容。
在 API_CHAIN 中可能找到
OpenProcess -> VirtualAllocEx -> WriteProcessMemory -> CreateRemoteThread
通常用于远程线程注入。
在 ATT&CK 中可能找到
T1055 Process Injection:攻击者可能将代码注入其他进程以逃避检测或提升权限。
在 IDA_SEMANTIC 中可能找到
当前样本的 sub_401000 函数存在跨进程内存写入和线程创建行为。
这样系统就同时得到了三类证据:
样本事实证据:当前函数确实调用了这些 API
行为链证据:这组 API 通常代表远程线程注入
ATT&CK 证据:远程线程注入可以映射到 T1055 Process Injection
这就是“多源知识检索”的意义。
七、检索后重排与证据融合
检索出来的结果不一定都是准确的。
比如系统搜索 CreateRemoteThread,可能返回很多内容:
远程线程注入
线程创建
进程操作
权限提升
Shellcode 执行
普通多线程编程
这些结果里,有些很相关,有些只是沾边。
所以检索之后还需要做重排。
1. 什么是重排
重排就是:
把最相关、最可信、最能解释当前函数的证据排到前面。
比如系统原本检索到:
1. Windows 线程创建介绍
2. CreateRemoteThread 用法说明
3. OpenProcess + VirtualAllocEx + WriteProcessMemory + CreateRemoteThread 远程线程注入链
4. ATT&CK T1055 Process Injection
5. 普通多线程编程
经过重排后,应该变成:
1. API_CHAIN:远程线程注入链
2. ATT&CK:T1055 Process Injection
3. IDA_SEMANTIC:当前函数调用链事实
4. CreateRemoteThread 单 API 说明
5. 普通线程创建介绍
因为前几条结果最能支撑“该函数可能是进程注入”的判断。
2. 什么是证据融合
证据融合就是:
把多个来源的证据合并起来,形成一个更稳定的判断。
比如只看到 OpenProcess,不能直接说它就是恶意行为,因为正常程序也可能调用这个 API。
但是如果同时看到:
OpenProcess
VirtualAllocEx
WriteProcessMemory
CreateRemoteThread
再结合 API_CHAIN 和 ATT&CK,那么这个判断就更有依据。
可以理解为:
单个 API:弱证据
多个 API 组成行为链:较强证据
行为链能映射到 ATT&CK:更强证据
当前样本函数中实际出现:最终落地证据
所以,证据融合的目的不是简单堆信息,而是让分析结论更可靠。
八、生成函数级 evidence / analysis
完成检索、重排和证据融合之后,系统就可以为每个函数生成分析结果。
例如对 sub_401000,系统可能生成:
{
"function": "sub_401000",
"evidence": [
"调用 OpenProcess 获取目标进程句柄",
"调用 VirtualAllocEx 在目标进程中分配内存",
"调用 WriteProcessMemory 向目标进程写入数据",
"调用 CreateRemoteThread 创建远程线程"
],
"analysis": "该函数具有典型远程线程注入特征,可能用于将恶意代码注入到其他进程中执行。",
"attack_mapping": {
"technique": "Process Injection",
"id": "T1055"
}
}
这里可以把两个概念区分开:
evidence = 我凭什么这么说
analysis = 我最终判断它是什么行为
也就是说,系统不是只输出一个结论,而是同时保留支撑结论的证据。
这对于恶意代码分析来说很重要,因为分析报告不能只写“该函数可疑”,还要说明它为什么可疑。
九、样本级聚合与能力链分析
前面的分析都是函数级的。
但是一个恶意样本通常不是只有一个函数。
可能存在多个函数分别完成不同任务:
sub_401000:反调试
sub_402000:解密 payload
sub_403000:进程注入
sub_404000:网络通信
sub_405000:注册表持久化
如果只分析单个函数,看到的是局部行为。
样本级聚合就是把所有函数的分析结果汇总起来,形成对整个样本的理解。
例如:
该样本包含以下可疑能力:
1. 反调试
2. Payload 解密
3. 进程注入
4. C2 通信
5. 持久化
能力链分析
能力链分析不是简单列清单,而是尝试把样本的行为按照攻击流程组织起来。
例如:
反调试
↓
解密 payload
↓
进程注入
↓
连接 C2
↓
执行远程命令
这样最终得到的报告就不只是:
发现 3 个可疑函数。
而是类似:
该样本可能先通过反调试检测运行环境,随后解密载荷,并通过进程注入方式将代码写入其他进程,最终建立网络通信能力。
这种描述更接近真正的恶意代码分析报告。
十、输出 Markdown / JSON 报告
最后,系统会把分析结果输出成两种格式:
Markdown
JSON
1. Markdown 报告
Markdown 更适合人工阅读。
例如:
# 样本分析报告## 一、样本概况## 二、可疑函数分析### sub_401000该函数调用 OpenProcess、VirtualAllocEx、WriteProcessMemory 和 CreateRemoteThread,表现出典型远程线程注入特征。## 三、ATT&CK 映射- T1055 Process Injection## 四、能力链总结该样本可能通过远程线程注入方式执行后续载荷。
2. JSON 报告
JSON 更适合程序继续处理,比如后续可视化、统计分析或者系统集成。
例如:
{
"sample": "1.bin",
"capabilities": [
{
"name": "Process Injection",
"functions": ["sub_401000"],
"attack_id": "T1055",
"evidence": [
"OpenProcess",
"VirtualAllocEx",
"WriteProcessMemory",
"CreateRemoteThread"
]
}
]
}
简单来说:
Markdown = 给人看
JSON = 给程序看
十一、当前支持的 RAG 后端
当前工程支持两种检索后端:
semantic:SentenceTransformer + FAISS
tfidf:TF-IDF 轻量检索后端
这两种方式的区别可以简单理解为:
semantic + FAISS:按语义找
TF-IDF :按关键词找
1. semantic:SentenceTransformer + FAISS
这条路线的大致流程是:
文本
↓
SentenceTransformer 转成语义向量
↓
FAISS 建立向量索引
↓
返回语义最相似的知识片段
它适合处理表达方式不同,但意思接近的情况。
比如函数摘要里写的是:
向目标进程写入数据并创建线程执行
即使没有直接出现“远程线程注入”这个词,语义检索也可能找到和“进程注入”相关的知识。
2. tfidf:TF-IDF
TF-IDF 的路线更偏关键词匹配:
文本
↓
分词 / 关键词权重计算
↓
计算关键词匹配相似度
↓
返回关键词最相关的知识
它适合处理 API 名称、ATT&CK 编号、关键术语等比较明确的内容。
比如:
WriteProcessMemory
CreateRemoteThread
T1055
这些词本身就很有区分度,用 TF-IDF 检索通常效果不错。
3. 两者为什么可以互补
在恶意代码分析场景里,单独使用一种检索方式都有局限。
TF-IDF 的优点是关键词命中准确,但不太理解语义。
Semantic 检索能够理解相近表达,但在某些 API 名称、技术编号等精确场景下,可能不如关键词匹配稳定。
所以两者结合起来更合适:
TF-IDF :保证关键术语、API、编号不容易漏
semantic + FAISS :补充语义相近但字面不同的内容
十二、完整流程总结
当前工程主流程可以总结为:
IDA / IDA-MCP
↓
导出当前样本或当前函数的静态语义事实
↓
构建 IDA_SEMANTIC raw / rag 数据
↓
联合 ATT&CK / API_CHAIN / IDA_SEMANTIC 进行多源检索
↓
检索后重排与证据融合
↓
生成函数级 evidence / analysis
↓
进行样本级聚合与能力链分析
↓
输出 Markdown / JSON 报告
如果换成更直白的话,就是:
先从 IDA 里拿到当前样本或函数的反汇编信息、API 调用和语义摘要;
然后把这些信息整理成系统可以保存和检索的数据;
接着拿这些函数行为去 ATT&CK、API 行为链和样本自身语义库里查相关知识;
查出来以后,把最相关、最能支撑结论的内容排到前面;
再把多个来源的证据融合起来,判断每个函数可能是什么行为;
最后汇总所有函数结果,形成样本整体能力链,并输出 Markdown 和 JSON 报告。
十三、一个具体例子
假设 IDA-MCP 从 IDA 中导出一个函数:
sub_401000调用 API:
OpenProcess
VirtualAllocEx
WriteProcessMemory
CreateRemoteThread
系统首先会把它整理成 IDA_SEMANTIC:
函数 sub_401000 存在跨进程内存分配、跨进程写入和远程线程创建行为。
然后系统拿这段信息去多源知识库里检索。
在 API_CHAIN 中可能找到:
OpenProcess -> VirtualAllocEx -> WriteProcessMemory -> CreateRemoteThread
通常用于远程线程注入。
在 ATT&CK 中可能找到:
T1055 Process Injection
攻击者可能将代码注入其他进程中执行。
在 IDA_SEMANTIC 中可以确认:
当前样本 sub_401000 实际调用了这些 API。
最终系统融合证据,得到函数级分析:
sub_401000 函数可能实现远程线程注入行为。该函数通过 OpenProcess 获取目标进程句柄,
随后调用 VirtualAllocEx 在目标进程空间分配内存,并通过 WriteProcessMemory 写入数据,
最后利用 CreateRemoteThread 创建远程线程执行载荷。该行为可映射到 ATT&CK T1055 Process Injection。
如果样本中还存在其他函数,例如:
sub_402000:IsDebuggerPresent 反调试
sub_403000:InternetOpenUrl 网络通信
sub_404000:RegSetValueEx 注册表持久化
那么样本级分析可能会总结为:
该样本整体具备反调试、进程注入、网络通信和注册表持久化能力,
可能先检测运行环境,再完成载荷注入,并通过网络通信与外部地址交互。
十四、最后的理解
这个系统本质上可以看成一个“自动辅助逆向分析器”。
人工分析时,我们一般是这样做的:
看 IDA 里的函数
看 API 调用
根据经验判断行为
查 ATT&CK 映射
整理证据
写报告
而当前工程就是把这个流程自动化:
IDA-MCP 抽取函数事实
RAG 检索相关安全知识
重排融合证据
生成函数分析
汇总样本能力
输出报告
所以它不是简单地调用大模型,也不是普通的问答系统。
它的核心在于:
通过 RAG 把恶意代码静态分析中的样本事实和外部安全知识连接起来,让系统能够基于证据生成函数级和样本级分析结果。
No responses yet