RAG:Retrieval-Augmented Generation,检索知识增强
前言介绍
先从资料库里检索相关内容
再基于这些内容来生成答案
检索增强生成
总体介绍
使用场景
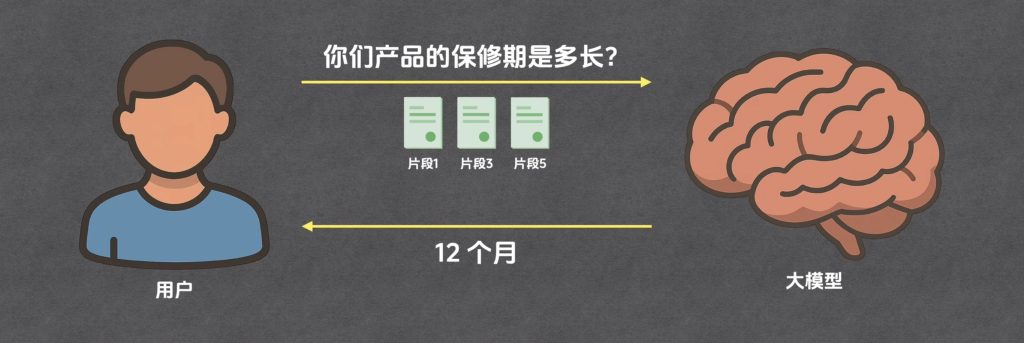
假设你要做一个智能客服
这个客服可以回答你们公司的所有产品的问题
首先这个客服内部一定有个大模型,像GPT-5,DeepSeek这种
但是光有模型可不够,因为模型是不知道公司的产品信息的
这时候你就会想,那如果我把产品手册也一起发送给大模型呢?
这里会存在一些问题
1.模型无法读取所有内容(上下文窗口大小)
2.模型推理成本高
3.模型推理慢
我们就可以考虑是不是把文档中相关的内容发送给模型呢?
这就引出了RAG
大致流程
首先RAG会将产品手册分为多个片段

当用户提出问题后,我们在这些片段中寻找相关内容
比如在上百个片段中可能只有三个片段与用户的问题相关

我们就把着3个片段挑出来,与问题一起发送给大模型
而不是整个文档
这里隐藏了很多细节
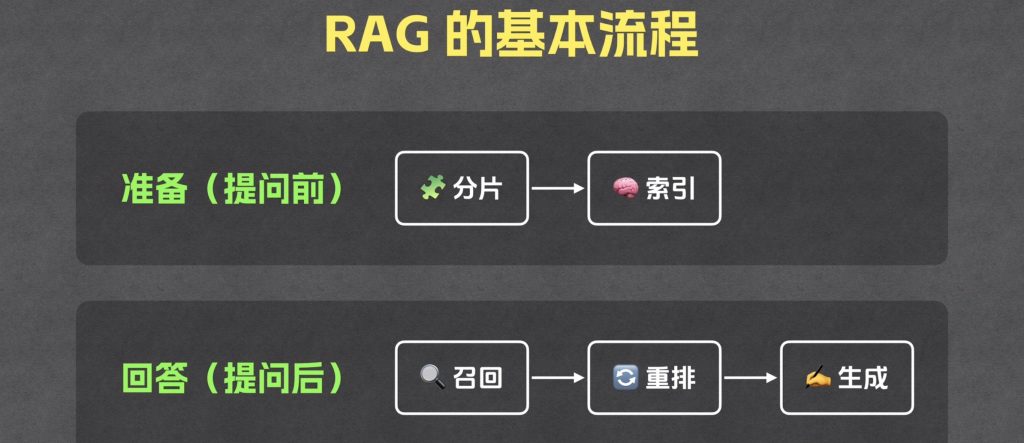
RAG的基本流程
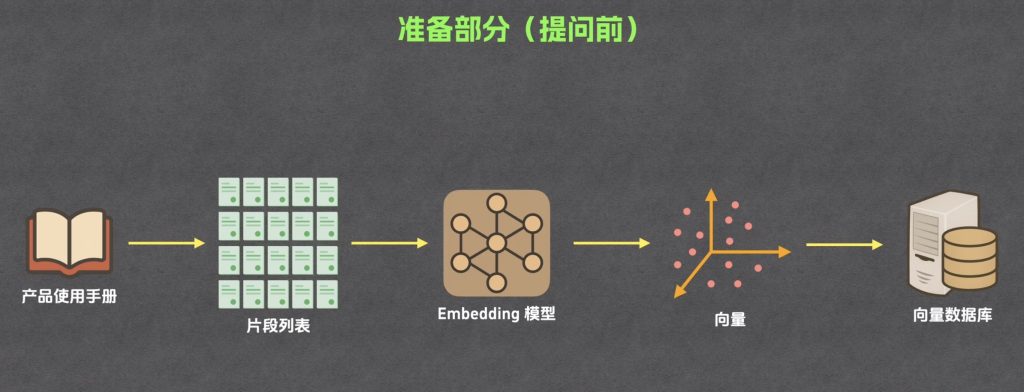
准备(提问前):我们要把相关的文档准备好,完成响应的预处理
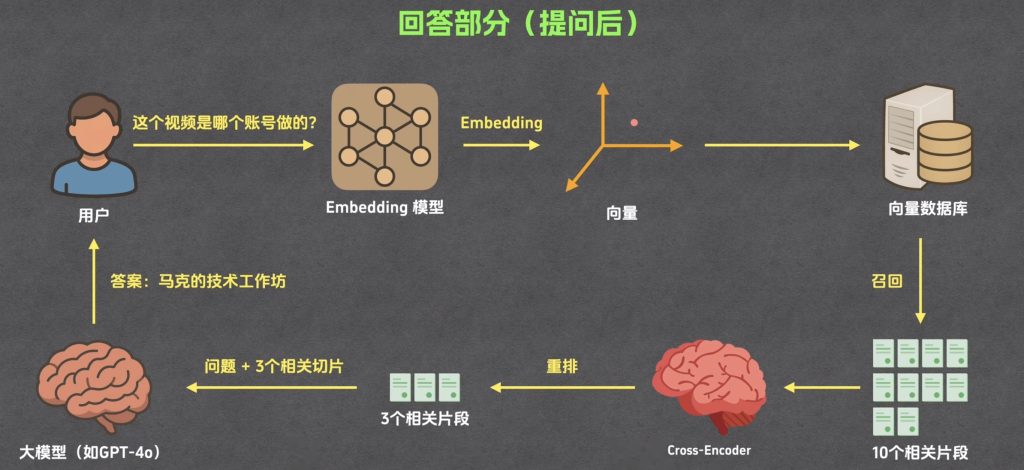
回答(提问后)
逐步拆解
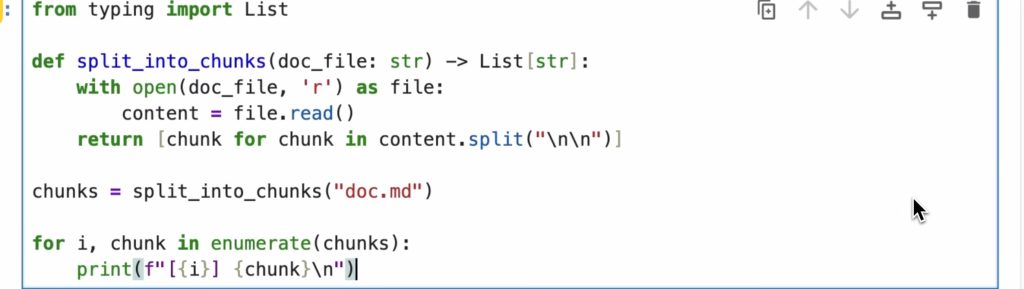
分片
分片的方式很多种

索引
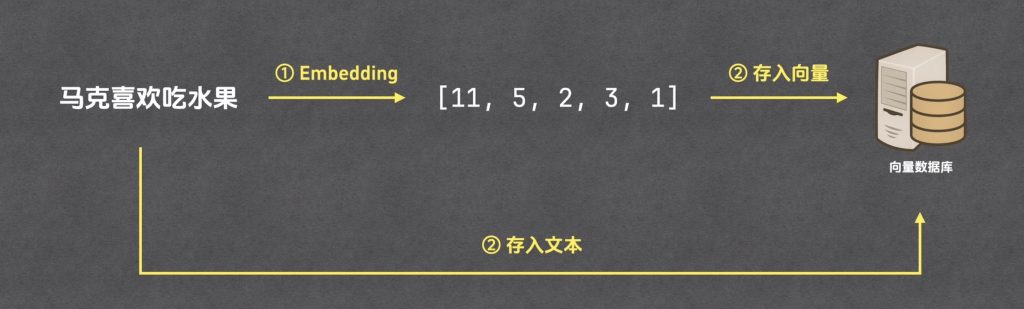
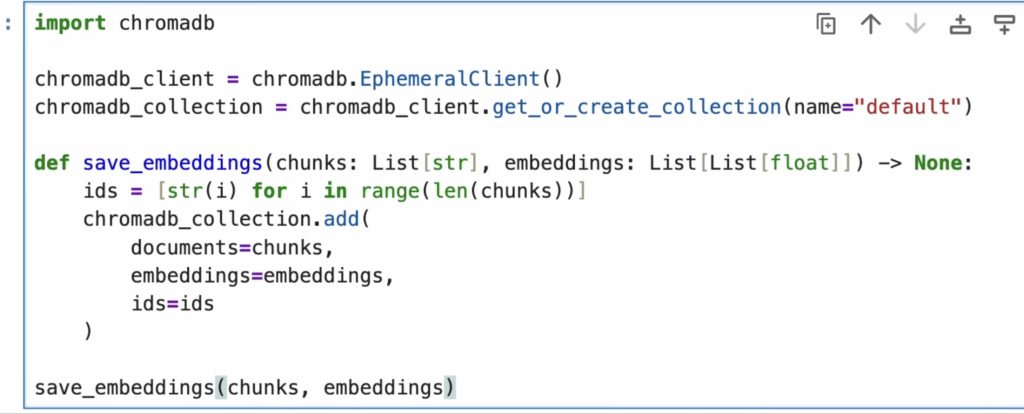
1.通过Embedding将片段文本转换为向量
2.将片段文本和片段向量存入向量数据库中
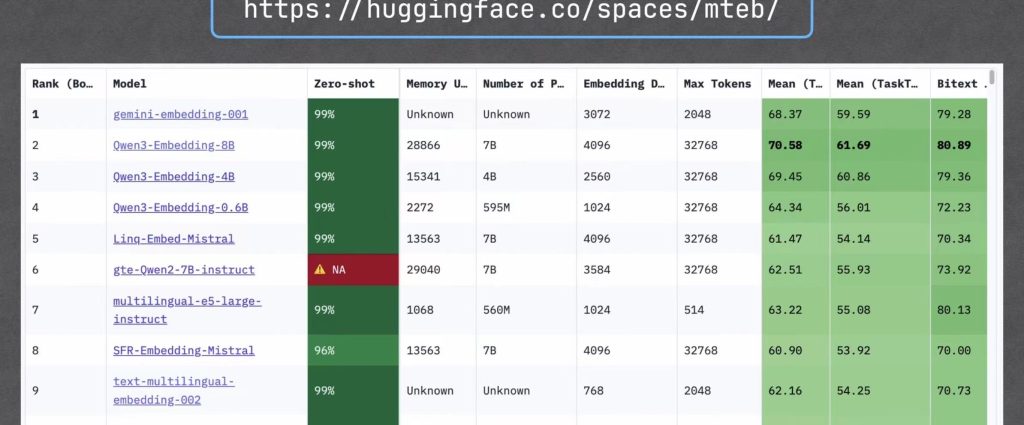
这里需要Embedding模型

召回
召回的结果就是返回与用户问题相似的片段
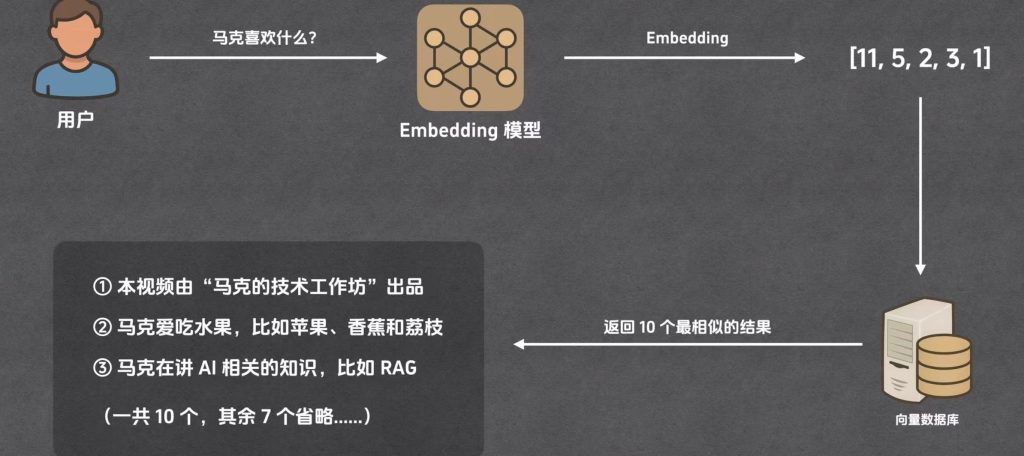
这里涉及到计算向量相似度了

计算问题的第一个参数永远是问题,第二个参数就是片段向量分别带入,计算出向量相似度


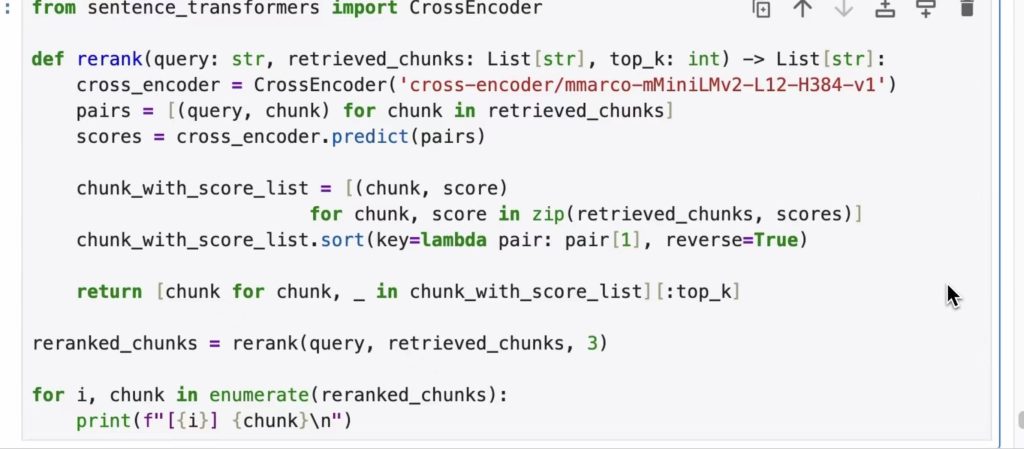
重排
重排就是重新排序,重排是从召回的结果里面重排出与问题最相似的3个结果
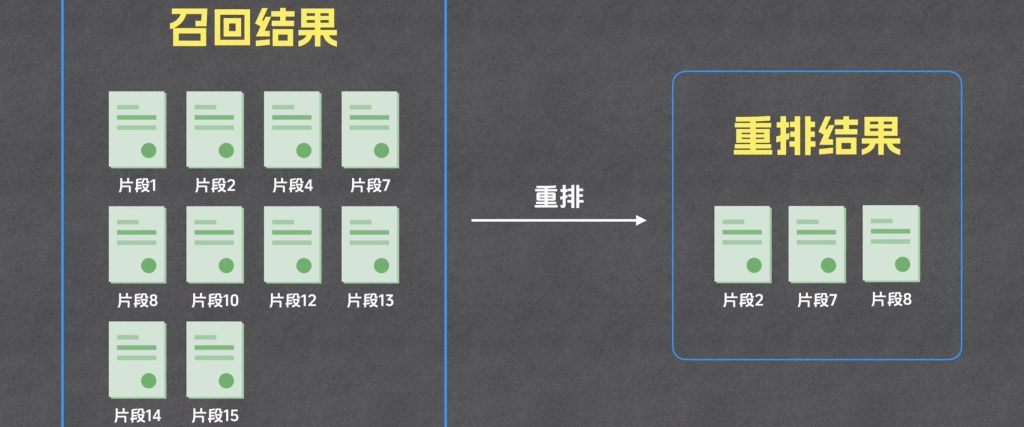
这里有个疑问为何不直接从召回阶段直接拿出3个最相似的结果呢?
一次挑出3个当然可以,但是效果不如召回加重排的方式好!why?
这是因为召回和重拍的计算逻辑是不一样的

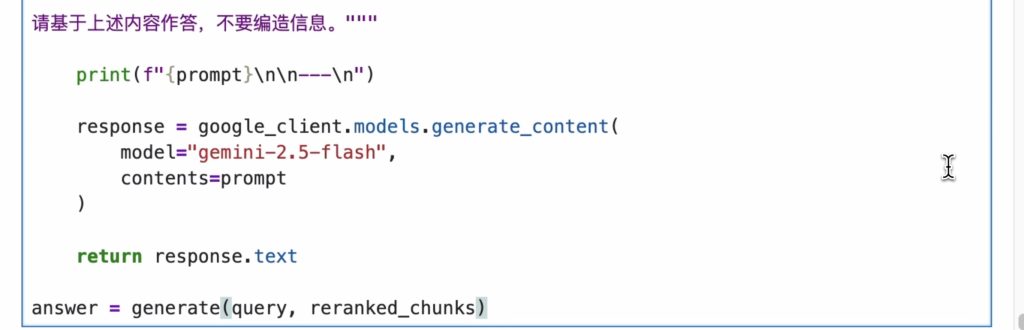
生成
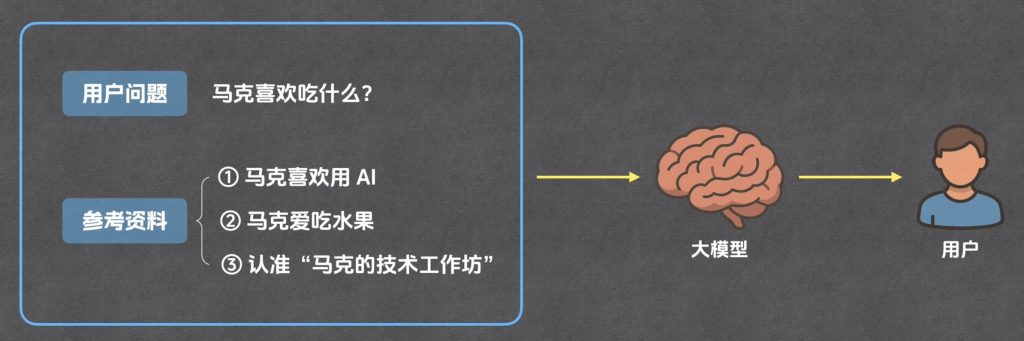
全链路回顾
提问前
提问后
以下是一个项目
https://github.com/MarkTechStation/VideoCode/tree/main/使用Python构建RAG系统/rag
分片
索引

存入向量数据库
召回

重排
生成
值得注意的是需要注册API key

学习链接:
【RAG 工作机制详解——一个高质量知识库背后的技术全流程】 https://www.bilibili.com/video/BV1JLN2z4EZQ/?share_source=copy_web&vd_source=6ee0547779d63e96ff044b5cc9392f44
No responses yet